데이터과학 유망주의 매일 글쓰기 — 일곱번째 일요일
범주형 데이터의 다양한 인코딩(Encoding)
# Encoding, # 범주형 데이터

오늘 한일:
이번 주 주말에는 그동안 내가 부족했던, 혹은 필요한 내용인데 탐구하지 못했던 내용들에 대해서 공부해 보기로 마음 먹었다. 그 중에 하나가 머신러닝모델의 성능을 높이기 위한 다양한 인코딩
(Encoding)기법이다. 이 기법은, 머신러닝모델이 숫자형 데이터만을 처리할 수 있기 때문에, 범주형 데이터를 숫자형 데이터로 변환시켜주는 역할을 한다. 인코딩이 얼마나 정확하게 데이터의 본질을 담아내면서도 데이터의 차원을 최소화하느냐에 따라, 머신러닝모델의 성능이 달라진다.
찾아보니, 이 인코딩 방법은 나의 예상보다 훨씬 더 다양한 형태로 존재했다. 매우 많은 방법들이 있었지만, 그 중에서 9가지 정도를 오늘 블로그에 공유하려한다.
일단 들어가기전, 필수적으로 이해해야할 것이 있는데, 범주형 데이터는 크게 Ordinal(일부 순서가 있는 형태)와 Nominal(특정 순서가 없는 형태)로 나뉘어 진다는 것이다. 따라서, 인코딩의 방법 역시, 데이터의 순서정보를 생성 및 유지하는 방법들과 그렇지 않은 방법들로 나뉘어진다.

범주형 데이터를 인코딩하는 방법은 여기 소개되지 않은 방법 외에도 여러가지가 있지만, 가장 널리 사용되는 대표적인 9개의 방법들을 꼽아보았다.
- One Hot Encoding
- Label Encoding
- Ordinal Encoding
- Helmert Encoding
- Binary Encoding
- Frequency Encoding
- Mean Encoding
- Weight of Evidence Encoding
- Probability Ratio Encoding
좀 더 원활한 설명을 위해, 아래처럼 Temperature 및 Color의 독립 변수들과, 타깃인 종속변수 Target을 가정해 보겠다.
# Pandas및 numpy 불러오기
import pandas as pd
import numpy as np# 데이터 준비
data = {
"Temperature": ["Hot", "Cold", "Very Hot", "Warm", "Hot", "Warm", "Warm", "Hot", "Hot", "Cold"],
"Color": ["Red", "Yellow", "Blue", "Blue", "Red", "Yellow", "Red", "Yellow", "Yellow", "Yellow"],
"Target": [1, 1, 1, 0, 1, 0, 1, 0, 1, 1]}df = pd.DataFrame(data, columns = ["Temperature", "Color", "Target"])
df

One Hot Encoding
각 범주를 0과 1의 벡터로만 표현하는 기법이다. 범주의 수만큼 벡터의 수가 생성되므로, 각 범주가 새로운 특성이 되어 표현된다. 그렇기 때문에 범주가 너무 많은 특성의 경우 데이터의 cardinality를 매우 크게 증가시킨다는 단점이 있다. 결과적으로, 알고리즘의 성능을 떨어뜨릴 가능성이 있으므로 이점에 주의해서 사용할 필요가 있다. 이 기능을 활용하는 방법은 pandas의 get_dummies나 sklearn.processing의 OneHotEncoder를 사용할 수 있다.
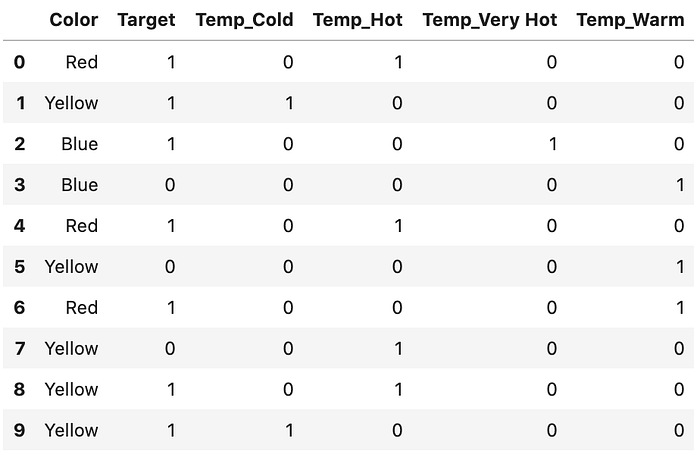
# Pandas의 get_dummies를 활용df = pd.get_dummies(df, prefix=["Temp"], columns=["Temperature"])
df
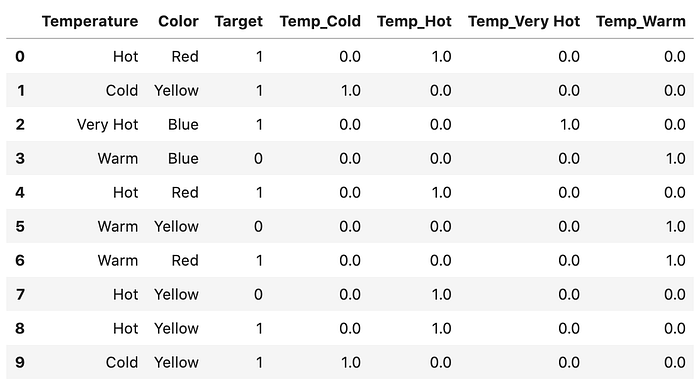
# sklearn.processing의 OneHotEncoder활용from sklearn.preprocessing import OneHotEncoder
ohc = OneHotEncoder()
ohe = ohc.fit_transform(df.Temperature.values.reshape(-1,1)).toarray()
df_OneHot = pd.DataFrame(ohe, coluns = ["Temp_" + str(ohc.categories_[0][i]) for i in range (len(ohc.categories_[0]))])dfh = pd.concat([df, df_OneHot], axis=1)
dfh
가장 널리 사용되는 인코딩기법으로써, N-1(N = 범주의 수) 만큼 범주가 특성이된다. 회귀 문제에서는, N-1이 사용된다. (첫 번째 혹은 마지막 칼럼 제거) 분류 문제에서는, 트리기반 알고리즘이 가능한 모든 특성들에 기반하여 트리를 생성하므로, 모든 N개의 칼럼을 사용하는 것을 권장한다. 선형 회귀는 학습을 하면서 모든 특성들에 접근하게 되며, 모든 더미 특성들을 전체적으로 다룬다. 즉 N-1개의 이진 변수들이 선형회귀에서 본래 범주형 변수에 대한 모든 정보를 제공한다는 것이다. 이러한 방식은 학습 중 모든 특성들에 접근하는 머신러닝기법에 활용될 수 있다. 예를 들어, Support Vector Machine, Neural Networks및 Clustering algorithms 등에 사용될 수 있다.
주의할 것은, 트리기반 알고리즘에서는 drop되어야 하는 라벨을 고려하지 않는다는 것이다. 그러므로, 범주형 변수들을 트리기반 알고리즘에 적용할 때에는, N개의 이진 변수로 먼저 인코딩한 후에 drop시키는 것이 좋다.
Label Encoding
각 범주가 1에서 N의 숫자를 갖는 인코딩 방식이다. N은 특성의 전체 범주의 수를 나타낸다. 각 범주 사이의 관계나 순서가 없더라도, 어느 정도의 관계나 순서가 있는 것으로 알고리즘은 인식한다. 예를 들어, 아래 예제에서는 Cold<Hot<Very Hot<Warm이 0<1<2<3 의 순서로 인코딩된다.
# Label Encoding
from sklearn.preprocessing import LabelEncoder
df["Temp_label_encoder"] = LabelEncoder().fit_transform(df.Temperature)
df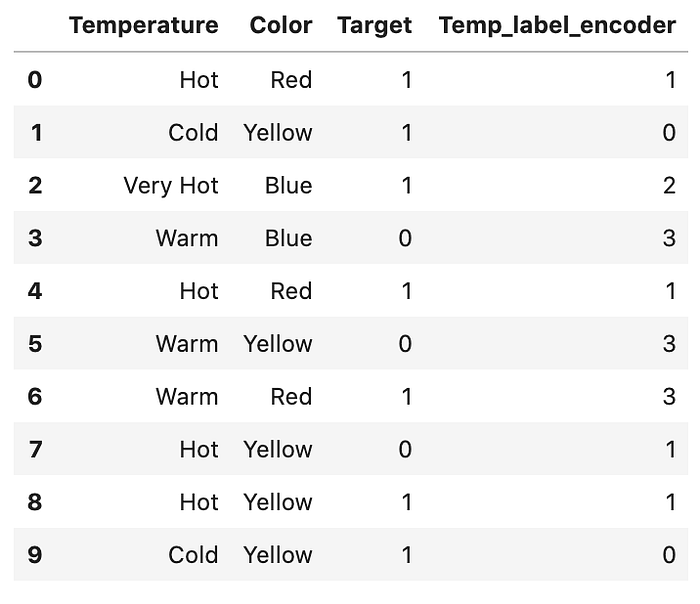
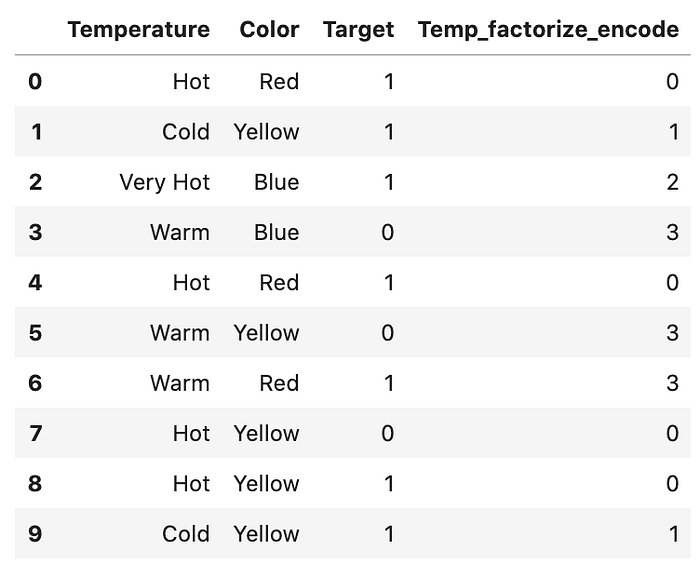
Pandas의 factorize도 같은 기능을 한다.
# Pandas의 factorizedf.loc[:, "Temp_factorize_encode"] = pd.factorize(df["Temperature"])[0].reshape(-1,1)df
Ordinal Encoding
변수의 순서를 유지하는 인코딩 방식이다. 순서가 중요한 특성에 대해서 사용되어야한다. Label Encoding과 비슷하지만, 이는 변수에 순서가 있음을 고려하지 않고 각 범주에 정수를 지정하는 것이므로 조금 다르다. Pandas는 Hot (0), Cold (1), “Very Hot” (2), Warm (3) 등으로 순서를 지정하지만, scikit-learn은 Cold(0), Hot(1), “Very Hot” (2), Warm (3)의 순으로 순서를 지정한다. 온도의 스케일을 순서로 본다면 “Cold”에서 “Very Hot”으로 가는 것이 맞을지 모르지만, Ordinal Encoding은 Cold(1) <Warm(2)<Hot(3)<”Very Hot(4)의 순으로 인코딩을 하며, 1부터 시작한다. Pandas를 사용한다면, 각 변수의 본래 순서를 dictionary를 통해 지정해 주어야한다. 이후에, dictionary에서 각 변수인 Key에 대해 행값을 지정해준다. (map을 활용)
# Mapping을 활용환 Ordinal Encoding
temp_dict = {"Cold": 1, "Warm": 2, "Hot": 3, "Very Hot": 4}
df["Temp_Ordinal"] = df.Temperature.map(Temp_dict)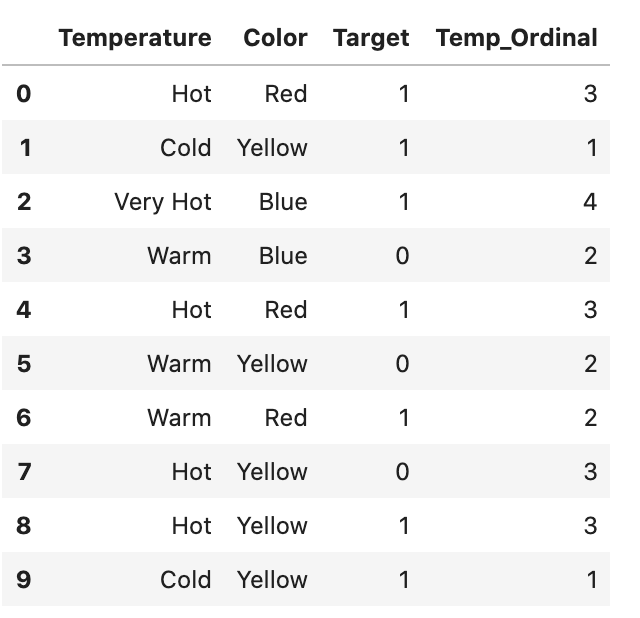
매우 직관적으로 느껴지지만, 코딩시 순차적인 값들을 지정해주어야하며, 그 순서에 따라 알맞은 점수 값들을 지정해 주어야한다.
Binary Encoding
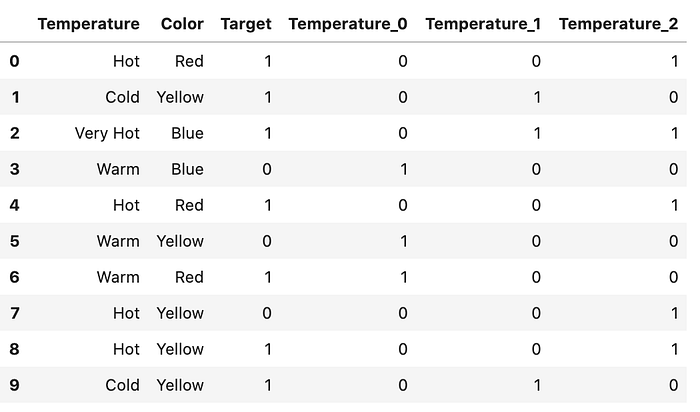
범주를 0과 1로 인코딩하는 방법이다. 각 숫자는 하나의 특성 칼럼을 만들어 낸다. n개의 범주가 있다면, 이 인코딩은 log(base 2)^n 만큼의 특성을 가진다. 예를 들어 4개의 특성이 있다면, 이진수로 인코딩될 경우 나오게 되는 특성은 3개가 된다. One Hot Encoding에 비교하면, 훨씬 더 적은 수의 칼럼을 필요로한다. (100개의 범주로 One Hot Encoding을 할 경우 100개의 특성이 생기지만, Binary Encoding으로는 7개의 특성만을 필요로한다.)
이 인코딩 방법은 아래와 같은 과정으로 진행된다.
- 범주는 먼저 1부터 시작하는 정수로 순서대로 인코딩된다 (데이터셋에서 나타나는 순서대로 인코딩되지만, 순서 정보가 있다는 의미는 아니다.)
- 정수는 이진수로 변환된다. 예) 3는 011, 4는 100
- 이진수의 숫자들은 별도의 칼럼을 형성한다.
- 예) hot -> order: 1 -> binary: 001 -> Temperature_0: 0, Temperature_1:0, Temperature_2:1
# Binary Encodingimport category_encoders as ceencoder = ce.BinaryEncoder(cols=[“Temperature”])dfbin = encoder.fit_transform(df[“Temperature”])df = pd.concat([df, dfbin], axis=1)df
Helmert Encoding
종속변수평균이, 이전 모든 수준에서의 종속변수평균과 비교되는 인코딩 방식이다. category_encoders 에 내재된 것은 Reverse Helmert Coding으로도 불린다. 한 레벨에서 종속변수평균이, 이전 모든 레벨에서의 종속변수평균과 비교된다. 그래서, 일반적인 순서로 행에지는 Helmert 인코딩 보다는, 역 방향의 “reverse” 라는 단어로 표현된다.
# Helmert Encoding
import category_encoders as ce
encoder = ce.HelmertEncoder(cols=['Temperature'], drop_invariant=True)
dfh = encoder.fit_transform(df['Temperature'])
df = pd.concat([df, dfh], axis=1)
df
Frequency Encoding
범주의 빈도를 라벨로 활용하는 방법이다. 만약 빈도가 타깃 변수를 예측하는데 있어 관련이 있는 정보일 경우, 모델은 데이터의 성질에 따라 비례율이나 반비례율의 정도를 인지하고 지정할 수 있다.
다음의 과정으로 진행된다.
- 변환하고자 하는 범주형 특성 선택
- 범주형 특성을 특정 그룹화(group by)하여 각 범주의 빈도수를 센다.
- 훈련 데이터에 더한다.
# Frequency Encoding
fe = df.groupby("Temperature").size()/len(df)
df.loc[:, "Temp_freq_encode"] = df["Temperature"].map(fe)
df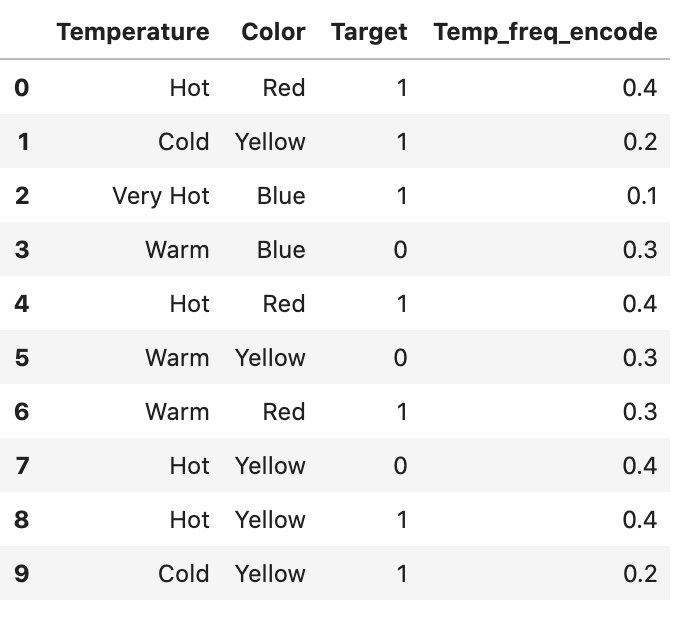
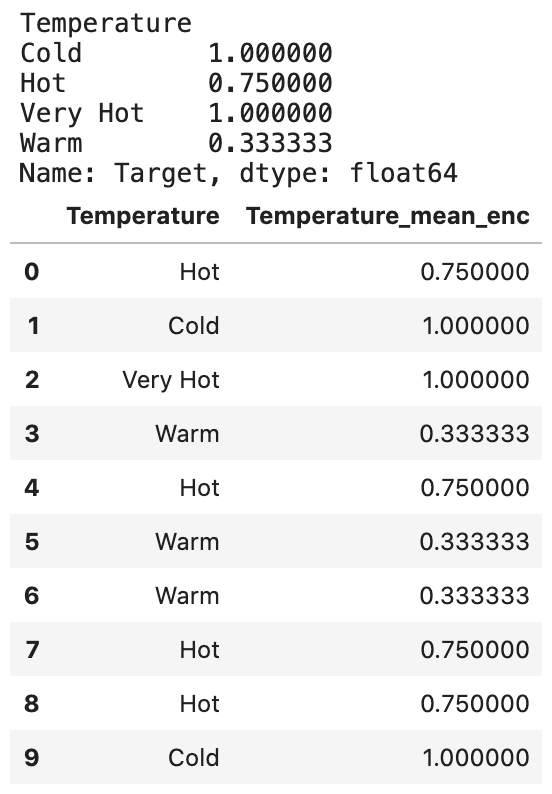
Mean Encoding
이 방법과 Target Encoding은 Kaggler들이 많이 사용하는 방법이다. 이 방법은 여러가지 형태로 적용될 수 있는데, 가장 기본적인 방법을 소개한다. 이 방법은 라벨 인코딩과 비슷한데, 라벨과 타깃이 직접적으로 연관이 있다는 차이가 있다. 예를 들어, mean target encoding은 훈련 데이터상의 각 특성 라벨 범주에 대한 타깃 변수의 평균값에 따라 결정된다. 이 인코딩 방법은 비슷한 범주사이에 있는 관계들을 표현한다는 특징이 있으나, 이 관계는 범주들과 타깃사이에만 국한된다. 이 방법의 장점은, 데이터의 부피에 영향을 주지 않는다는 장점이 있으며, 빠른 학습에 효과적이다. 그러나 보통, 이 방법은 overfitting이 많이 나타나기로 악명이 높다. 그러므로, cross validation 및 정규화(regularization)가 대부분 반드시 같이 사용되어야 한다.
다음의 과정을 거치게 된다.
- 변환시키고자하는 범주형 변수를 선택한다.
- 범주형 변수를 그룹화(group by)시키고, 타깃 변수에 대한 총합(sum) 합계를 얻는다. (예: “Temperature” 변수의 각 범주에 대한 1의 총합)
- 범주형 변수를 그룹화 시키고, 타깃에 대한 빈도수 (count) 합계를 얻는다.
- 2의 결과를 3으로 나누고, 훈련데이터의 본래 범주 값들에 업데이트한다.
예: Temperature: “Hot” -> Sum of target: 3 -> count of target 4 -> Mean: 0.75 -> Temperature: 0.75
# Mean Encoding을 위한
mean_encode = df.groupby("Temperature")["Target"].mean()
print(mean_encode)
df.loc[:, "Temperature_mean_enc"] = df["Temperature"].map(mean_encode)
df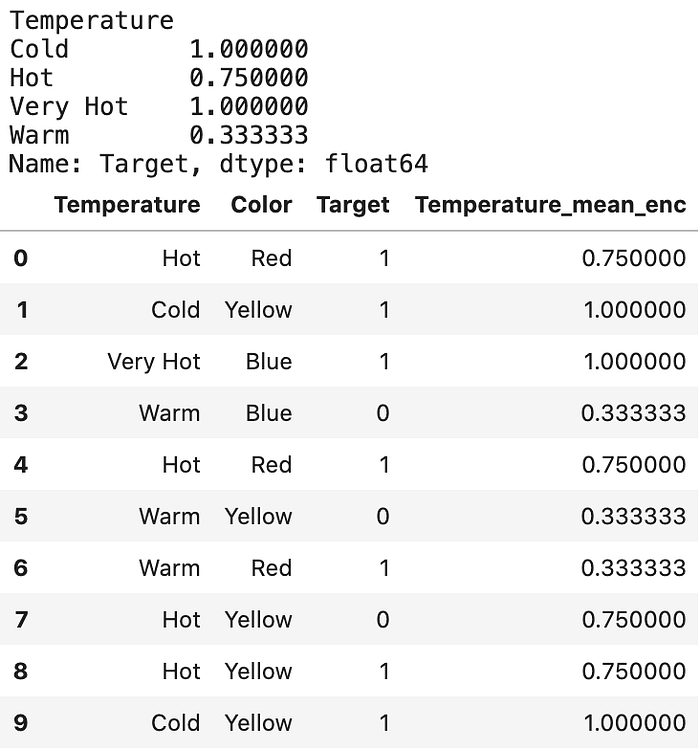
이 방법은 라벨내 타깃을 담고 있지만, 라벨은 타깃과 상관관계에 있지 않다. 범주가 많은 경우, 이 방법은 데이터를 훨씬 더 단순화시킬 수 있다는 장점이 있다. 이 방법은 범주를 그룹화하는 특성이 있는데, Label Encoding과 비교해 랜덤하게 그룹화 된다는 차이점이 있다. 이 타깃 인코딩에 대해서는 다양한 형태가 존재하는데, smoothing이 그중에 하나이다.
# 1. 평균을 계산Mean = df[“Target”].mean()# 2. 각 그룹에 대한 값들의 빈도와 평균을 계산Agg = df.groupby(“Temperature”)[“Target”].agg([“count”, “mean”])Counts = agg[“count”]Means = agg[“mean”]Weight = 100# 3. “smooth”한 평균을 계산Smooth = (counts * means + weight * mean) / (counts + weight)# smooth한 평균에 따라 각 값을 대체하는 것print(smooth)df.loc[:, “Temperature_smean_enc”] = df[“Temperautee”].map(smooth)
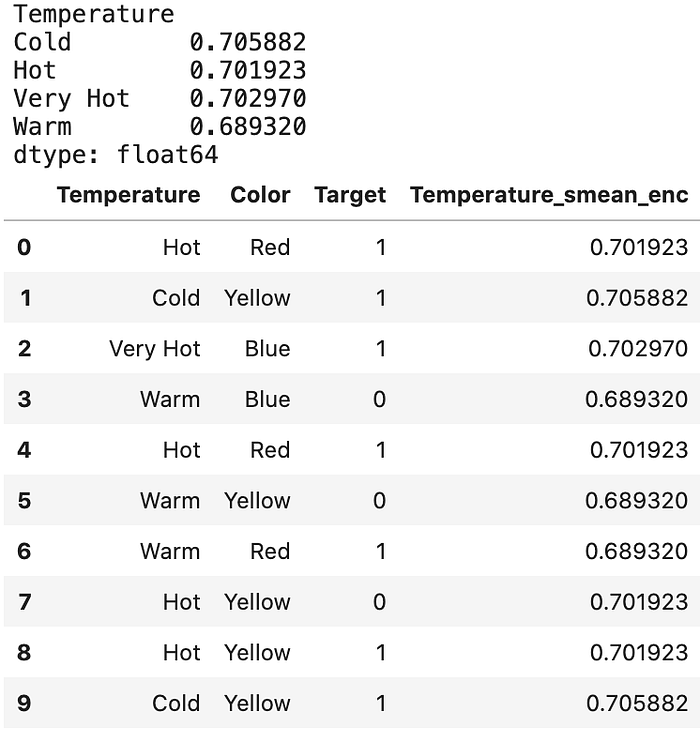
Weight of Evidence Encoding (WoE) [근거의 무게기반 인코딩]
이 방법은 각 범주들이 얼마나 잘 그룹화 되었는지에 대한 “그룹화 강도(strength)”를 기준으로 인코딩을 하는 방법이다. 예를 들어, 이 방법을 통해 신용 및 재정 상태를 기반으로, 개인 및 기업의 채무 불이행 위험성을 평가하는데 유용한 모델을 만들 수 있다. Weight of Evidence (WoE)는 근거가 가설을 얼마나 뒷받침하는지를 측정한다.

P(좋은 그룹)/P(나쁜 그룹) = 1, 이면 WoE 는 0이 된다. 이는 특정 그룹에 대한 결과가 랜덤할 때 나타난다. 만약 P(좋은 그룹) < P(나쁜 그룹)일 경우, WoE < 0 이며 odds의 비율 < 1이 된다. 반대로, 한 그룹에서 P(좋은 그룹) > P(나쁜 그룹)이면, WoE > 0이다. WoE는 log의 odds가 Logit transformation이므로, 로지스틱 회귀문제에 적합하다. (ln(좋은 그룹의 확률/나쁜 그룹의 확률))
그러므로, 로지스틱 회귀에서 WoE 코딩된 예측을 사용하면, 같은 스케일로 인코딩된 모델을 만들 수 있다. 선형 로지스틱 회귀의 공식에서 변수들은 직접적으로 비교될 수 있다.
이 방법의 장점은 아래와 같다.
- 독립 변수를 종속 변수와 관계할 수 있도록 변환시킨다. 또한 단조로운(monotonic) 관계를 위해서는 이들을 그 어떤 순서(예: 1, 2, 3, 4,…)로도 다시 인코딩하면 되지만, WoE는 로지스틱 회귀의 특성처럼 “로지스틱”한 스케일로 범주들을 순서화할 수 있다.
- 비연속적인(discrete) 값들이 너무 많은 변수는(밀도가 낮은 변수), 범주로 그룹화 될 수 있다(밀도가 높은 변수). 그리고 WoE는 전체 카테고리에 대한 정보를 표현할 수 있다.
- WoE는 표준화된 값이므로(standardized value), 각 범주의 종속 변수에 대한 일변향효과(univariate effect)는 범주들과 변수들 사이에서 비교된다. (예: 기혼자들의 WoE와 육체 노동자들의 WoE를 비교할 수 있다.)
반대로 단점들은 아래와 같다.
- 일부 범주만 binning을 하므로 정보의 훼손 (변형)이 생긴다
- “일변형(univariate)” 계산이므로, 독립 변수들 사이의 상관관계를 고려하지 않는다.
- 범주가 어떻게 생성되었는지에 따라, 변수들의 over-fit 효과가 나타나기 쉽다.
# 각 범주가 target = 1일 확률(좋은(Good) = 1일 확률)을 계산한다.woe_df = df.groupby(“Temperature”)[“Target”].mean()woe_df = pd.DataFrame(woe_df)# 칼럼의 이름을 "Good"으로 바꾸어 좀 더 이해하기 쉽게 한다.woe_df = woe_df.rename(columns = {“Target”: “Good”})# "Bad"는 "Good"의 확률에 반대되는 부분의 확률이다.woe_df[“Bad”] = 1-woe_df.Good# 분모에 최소한의 값을 더하여 0으로 나뉘는 일을 막는다.woe_df[“Bad”] = np.where(woe_df[“Bad”] == 0, 1e-6, woe_df[“Bad”]# WoE를 계산한다. woe_df[“WoE”] = np.log(woe_df.Good/woe_df.Bad)woe_df
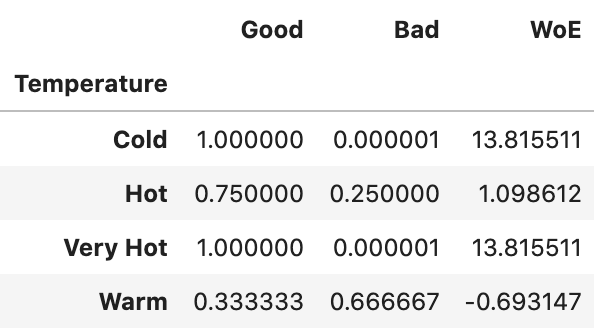
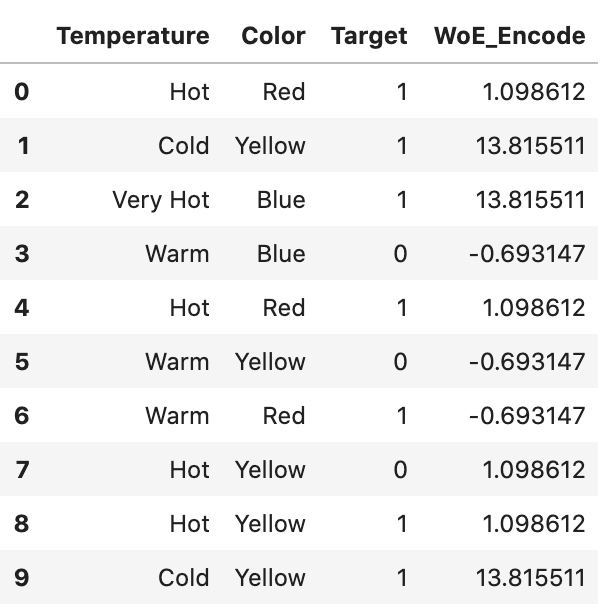
각 그룹에 대해 WoE를 계산한다면, 데이터프레임에 맵핑할 수 있다.
# 각 범주에 대한 WoE를 계산하면, 데이터프레임에 맵핑할 수 있다.df.loc[:, “WoE_Encode”] = df[“Temperature”].map(woe_df[“WoE”])df
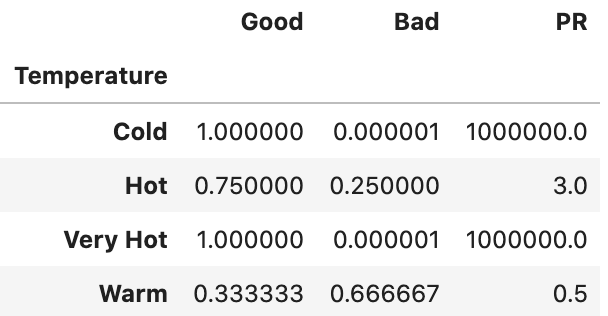
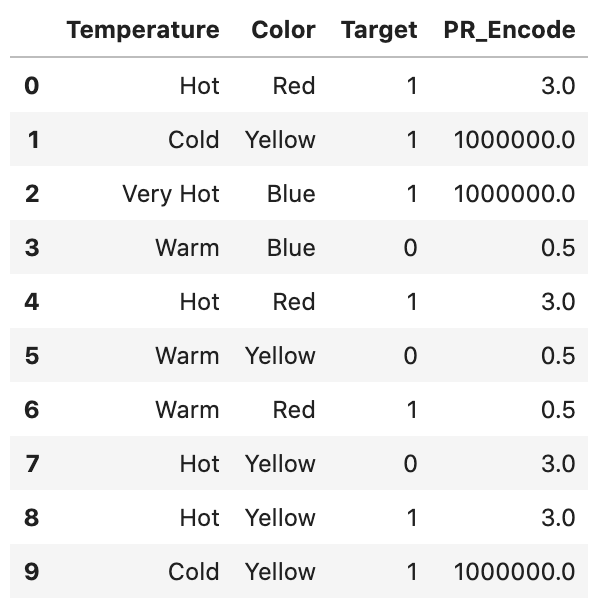
Probability Ratio Encoding(확률 비율 인코딩)
WoE와 사용법이 비슷하나, log가 아닌 좋은 그룹의 확률과 나쁜 그룹의 확률 비율 자체만이 사용된다는 차이가 있다. 각 라벨에 대해, “타깃=1”인 평균을 찾는다. 이것은 타깃이 1이 될 확률 P(1)을 뜻한다. 또한 타깃=0일 확률인 P(0)를 계산한다.
이후에, P(1)/P(0)를 계산하고 라벨을 이 비율로 대체한다. 주의할것은, P(0)에 최소한의 값을 보장해 주어야 0으로 나뉘는 것을 피할 수 있으며, 타깃=0이 아예 없는 것을 피할 수 있다.
# 각 범주에 대해, 타깃 = 1인 확률(좋은(Good) = 1일 확률을 찾는다)을 찾는다.pr_df = df.groupby(“Temperature”)[“Target”].mean()pr_df = pd.DataFrame(pr_df)# 칼럼의 이름을 "Good"으로 바꾸어 좀 더 이해하기 쉽게 한다.("Bad"는 "Good"의 확률에 반대되는 부분의 확률이다.)pr_df = pr_df.rename(columns = {“Target”: “Good”}}pr_df[“Bad”] = 1-pr_df.Good# 분모에 최소한의 값을 더하여 0으로 나뉘는 일을 막는다.pr_df[“Bad”] = np.where(pr_df[“Bad”] == 0, 1e-6, pr_df[“Bad”])# 확률 비율을 계산한다. pr_df[“PR”] = pr_df.Good/pr_df.Badpr_df
# 계산된 각 범주의 확률 비율을 본래 데이터에 더한다.df.loc[:, “PR_Encode”] = df[“Temperature”].map(pr_df[“PR”])df
각 상황에서 어떤 방법을 사용하는 것이 이상적일까?
머신러닝에서 주의할 것은, 그 어떤 종류의 데이터에도 100% 예측을 할 수 있는 완벽한 방법은 없다는 것이다. 가장 좋은 방법은 여러가지 인코딩 방법을 사용해 보면서, 가장 좋은 결과를 내는 방법을 찾는 것이다. 이를 위해서는 EDA를 통해 데이터를 잘 분석해보고, 그 데이터셋의 특징을 가장 잘 표현할 수 있는 기법을 찾는 것이 최선이다. 다양한 기법을 다양한 상황에 적용하는 연습을 해 볼 수록, 어느 상황에 어느 기법을 써야 최적의 모델을 만들 수 있는지에 대한 감을 잡을 수 있다.
그렇다면, 타깃 데이터가 주어지지 않는, 소위 “Kaggle 챌린지” 같은 상황에는 어떠한 인코딩을 사용하는 것이 좋을까? 가장 좋은 방법은 훈련시에 생성된 mapping 값들을 활용하는 것이다. 훈련데이터를 scaling하고 normalizing 함으로써 테스트데이터를 정규화시키는 것과 같은 효과를 얻는 것과 비슷한 개념이다. Time pre-processing의 테스트를 위해 사용한 맵핑 기법을 활용한다. 각 범주에 대해 맵핑된 값들을 dictionary로 생성하고 테스트 시에 dictionary를 활용한다. 아래 처럼 mean encoding을 사용할 수 있다.
# 훈련 시간(Training Time)import pandas as pd
import numpy as np
data = {
"Temperature": ["Hot", "Cold", "Very Hot", "Warm", "Hot", "Warm", "Warm", "Hot, "Hot", "Cold"],
"Target": [1, 1, 1, 0, 1, 0, 1, 0, 1, 1]}df = pd.DataFrame(data, columns = ["Temperature", "Target"])mean encode = df.groupby("Temperature")["Target"].mean()
print(mean_encode)
df.loc[:, "Temperature_mean_enc"] = df["Temperature"].map(mean_encode)
df
# 테스트 시간(Testing Time)
print(mean_encode)# 타깃이 없는 테스트 데이터를 활용
test_data = {"Temperature": ["Hot", "Cold", "Very Hot", "Warm", "Hot", "Warm", "Warm", "Hot", "Hot", "Cold"]}
dft = pd.DataFrame(test_data,columns = ["Temperature"])# 맵 데이터를 사용하여 이전에 훈련시 mean encoding로 생성된 데이터에 Temperature를 맵핑한다
dft["Temperature_mean_enc"] = dft["Temperature"].map(mean_encode)
dft
결론
특정 머신러닝모델에서, 모든 종류의 데이터에 모든 상황에 잘 되는 인코딩 기법은 없다는 것을 주의해야한다. 데이터과학자들은, 어떤 모델이 어떤 상황에서 어떤 데이터에 가장 좋은 예측을 할지에 대해 계속적으로 연구하고 실험해야 한다. 테스트 데이터의 타깃이 다른 범주들을 가지고 있다면, 훈련 데이터의 타깃 특성이 가지는 모습과 다르기 때문에, 이 중 몇 개의 기법은 큰 효과를 보지 못할 수 있다. 인터넷에 존재하는 다양한 커뮤니티에 좋은 참고자료들이 있지만, 그 중 어떤 것도 항상 모든 상황에 잘 된다고 볼 수는 없다. 다시 언급하지만, 가장 좋은 방법은 좀 더 작은 규모의 데이터 셋에서 가능한 모든 인코딩 방법을 시도해보고, 데이터의 어느 특성에 인코딩 효과를 집중시킬 것인지를 찾는 것이다. 아래 참조란에서 이 블로그를 쓰는데 참조한 All about Categorical Variable Encoding의 Cheat Sheet를 참조하면 좋다.
앞으로 할일:
오늘은 다양한 인코딩 방법에 대해 공부해 보았다. 사실 여기 소개한 것 말고도 상당히 많은 인코딩 기법이 존재하며, 지금 이 순간도 누군가가 대학원 같은 곳에서 더 효율적이고 새로운 인코딩 방법을 연구하고 있을지도 모른다.
내가 지난 2주간 머신 러닝의 기초를 배우면서, 또 다양한 교육 자료를 참조하면서 얻은 결론은, 모든 상황에 100% 효율적인 도구를 찾는 것은 불가능에 가깝다는 것이다. 대신, 각 상황에 가장 알맞는, “최적의"솔루션은 찾을 수 있다. 머신러닝분야에서는 특히 정해진 공식이 없고, 각 인코딩 방법이 안에서 데이터를 처리하는 방식을 속속들히 알기 쉽지 않다. 가장 좋은 방법은, 모든 인코딩 방법을 최대한 다양한 데이터에 시도해 보면서 감을 얻는 것이다. 다른 모든 분야와 마찬가지로, 데이터과학도 경험이 매우 중요하다. 그래서 도메인 지식이 그 무엇보다도 중요하다는 생각이 든다. 다양한 경험이 많으면 많을 수록, 더 좋은 데이터과학자가 될 수 있다는 것을 다시 깨닫는다.
무엇보다도, 오늘 글을 쓸 수 있게 좋은 참고자료를 제공해 주신 Towards Data Science의 Baijayanta Roy에 감사하다. 이런 선배들이 좋은 자료를 공유해주어, 나 같은 새내기 데이터과학자들이 발전할 수 있음에 큰 감사를 표한다.
이 블로그는 Baijayanta Roy의 All about Categorical Variable Encoding이라는 기사를 참조하였습니다.
참조:
